Exam 8 OneStop - when to use relativities vs pure premium

Working thru the problems on the Exam8_OneStop. Trying ot understand when / how to normlize and focus on relative model error vs. pure model prediction.
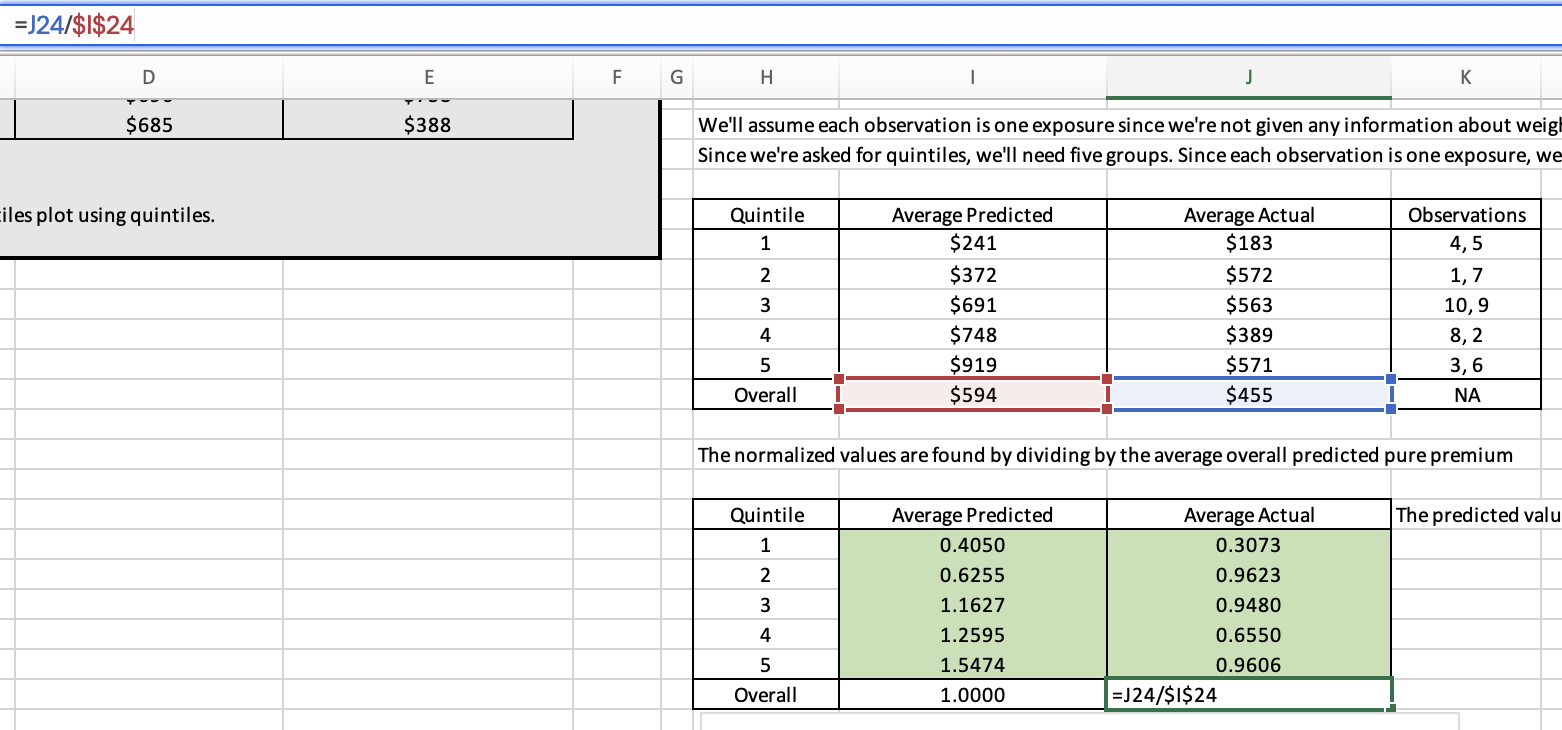
GLM Quantiles - I was surprised that each column here was normalized by the overall predicted premium. Thought practice was to create relativities for each column
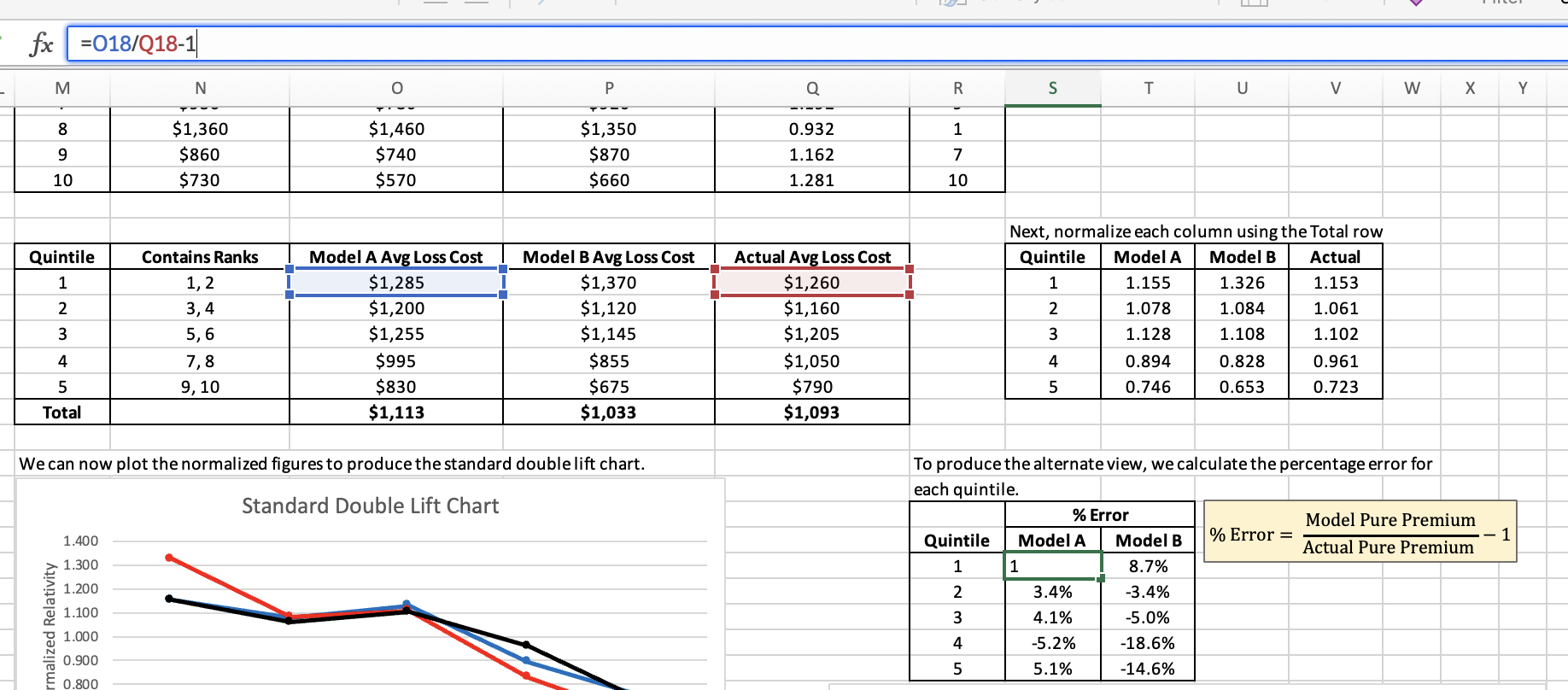
on GLM_DLC - here we create relativities for each column. However, the % error calcs don't use them. These use the pure prediction - so the differences in the overall predictions by column become part of the differential.
Comments
Great questions!
When we're producing quantile plots we're only using the output of a single model. If we want to compare quantile plots for two different models then we need to ensure they're on the same basis/scale. A contrived example would be the only difference between the two models is one of them has a set of relativities for a rating variable which were selected 10% higher than the other. In this case, the two models should perform the same as the only difference is really a matter of base rates. By normalizing the quantile plot by the overall predicted premium we correct for this which allows us to directly compare two quantile plots.
For double lift charts we're comparing two models at the same time. Again, the idea that the base rates might be different is at play which is why we normalize by total row for each model. This allows us to put everything on the same basis. The sort ratios aren't impacted by this because although their magnitude would change if we didn't normalize first, the order of the quintiles wouldn't change.
The GLM text is really vague on these issues of normalization. When it comes to the % error approach I think it's okay that we're not normalizing provided we realize the overall rate adequacy of the two models likely differs. The text says "the winning model is the one with the flatter line centered at y=0..." To me, this implies both models have been adjusted to the same overall level of rate adequacy. If we didn't do this then we'd want the model which has the flattest line but isn't necessarily centered at y=0.
When working to validate GLMs in my career the standard practice has been to apply an off-balance factor to the model output to adjust each record by the same amount so that the total predicted loss equals the total actual loss before forming quantile plots or double lift charts (i.e. a form of normalization)